【ACL 2021】《 RADDLE:An Evaluation Benchmark and Analysis Platform for Robust Task-oriented Dialog Systems》实验分析
英文标题:RADDLE:An Evaluation Benchmark and Analysis Platform for Robust Task-oriented Dialog Systems
中文翻译:健壮的任务型的对话系统的评估基准和分析平台
原文链接: https://arxiv.org/pdf/2012.14666.pdf
文章目录
- 【ACL 2021】《 RADDLE:An Evaluation Benchmark and Analysis Platform for Robust Task-oriented Dialog Systems》实验分析
- Experiment
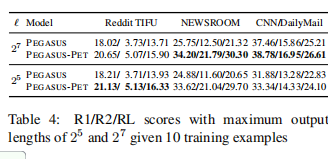
- 1.所有raddle任务中基线的总体结果
- 2 对SOLOIST引入不同程度噪声语料
- 3 对SOLOIST引入不同程度语音错误。
- 4 对比GPT2 SOLOIST对unseen实体识别
- 5 对比GPT2 SOLOIST不同域中引入OOD语料
- 6 不同类型模型对人类评估和语料库评估之间的差距
- Conclusion
本文主要提出了一个任务型端到端对话系统模型鲁棒性的判别基准–Raddle,通过将标准的训练测试语料替换成带有噪声的语料,以量化模型其鲁棒性。
引入的噪声分为以下类别:
- Parapharse 用其他词重新陈述文本;
- Verbosity 冗余的词语来表达意图
- Simplification 简洁的话语表意图;
- Typos 不合规的缩写的。
- Speech Errors :实际ASR过程中识别,合成错误等带来的输入文本错误
- Unseen Entities :在知识库中,但模型未见过的实体
- Out-of-Domain Utterances :域外意图。
遗憾的是发现该平台并没有开放测试( link),介绍参考礼文学长的阅读笔记(link),本文关注于实验部分
Experiment
本文引入DAMD,GPT-2,SOLOIST作为3个基线模型,训练时在raddle上进行finetune,每个域单独训练。
1.所有raddle任务中基线的总体结果

如图所示,GPT-2优于基于DAMD。突出了预训练模型的有效性。SOLOIST是性能始终表优于GPT-2。这些有力的表明对话语料库上的大规模任务预训练对于任务适应与鲁棒性至关重要。从speech ERR的准确率大幅下降,说明实际ASR十分敏感且对模型准确率影响剧烈。OOD指标的提升,说明特定任务的预训练可以提高模型对域外话语的鲁棒性。
2 对SOLOIST引入不同程度噪声语料


虽然在Env-2和Env-3上综合分数有所下降,但SOLOIST仍然保持着较高水平。作者提出DST是对话模型鲁棒性的主要瓶颈。提高鲁棒性的一个可能途经是将对抗性训练(Liu等人,2020)应用于特定任务的预训练。
3 对SOLOIST引入不同程度语音错误。

引入高错误率以模拟实际嘈杂环境下的噪声,SOLOIST性能依旧客观。作者认为在对话预训练中添加语音模态(speech modality)可以增强对语音错误的鲁棒性。
4 对比GPT2 SOLOIST对unseen实体识别
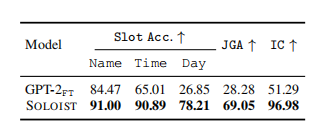
我们观察到,在这个受控实验中,GPT-2FT无法准确识别日期一类的实体,导致联合目标精度和意图识别结果较差。相比之下,对于特定任务的预训练,SOLOIST大大提高了性能。
5 对比GPT2 SOLOIST不同域中引入OOD语料

在DSTC域中,GPT-2FT在SOLOIST中的表现相似。10%时SOLOIST优于GPT2。在其他领域,独奏者的表现始终优于GPT-2FT。在Reddit和twitter域中,50% OOD数据训练书,SOLOIST高出20个点,这表明SOLOIST比GPT-2的域外话语方面更具鲁棒性。
作者提出一个鼓舞人心的结果是,注入OOD数据可以提高DST的性能。虽然特定任务的预训练已有助于OOD检测,但将open domain数据引入到预训练中,或从开放域对话模型(如DialoGPT)初始化,可能会进一步提高对话模型的鲁棒性。
6 不同类型模型对人类评估和语料库评估之间的差距

DSTC为人工与语料库评估差异的比赛,区域面积表明了对不同类型模型的人类评估和语料库评估之间的差距,DSTC8中,team5使用GPT2,转入人工评估性能下降最小,说明预训练对于鲁棒性的重要性,而到DSTC9中已有大量参赛队伍使用预训练模型,但仍与人工评估有差距,说明模型对噪声十分敏感,进而证明对模型引入鲁棒性评估的重要性。
Conclusion
作者分别对引入不同噪声进行了总实验,并针对不同比率噪声语料引入,ASR中的语音错误,unseen enities,OOD进行了分实验,实验表明SOLOIST模型鲁棒性较强,且DST与ASR模块对模型鲁棒性至关重要,而对抗训练,特定任务的预训练,ASR中引入语音模态等方法对模型鲁棒性增强有正向作用。在OOD方面,将open domain数据引入预训练或从开放域对话模型进行初始化,可能有正向作用。