文章目录
- 为什么需要数据库设计
- 范式
- 范式简介
- 范式都包括哪些
- 键和相关属性的概念
- 第一范式(1st NF)
- 第二范式(2nd NF)
- 第三范式(3rd NF)
- 反范式化
- 概述
- 应用举例
- 反范式化的新问题
- 反范式的适用场景
- BCNF(巴斯范式)
- 案例
为什么需要数据库设计


范式
范式简介
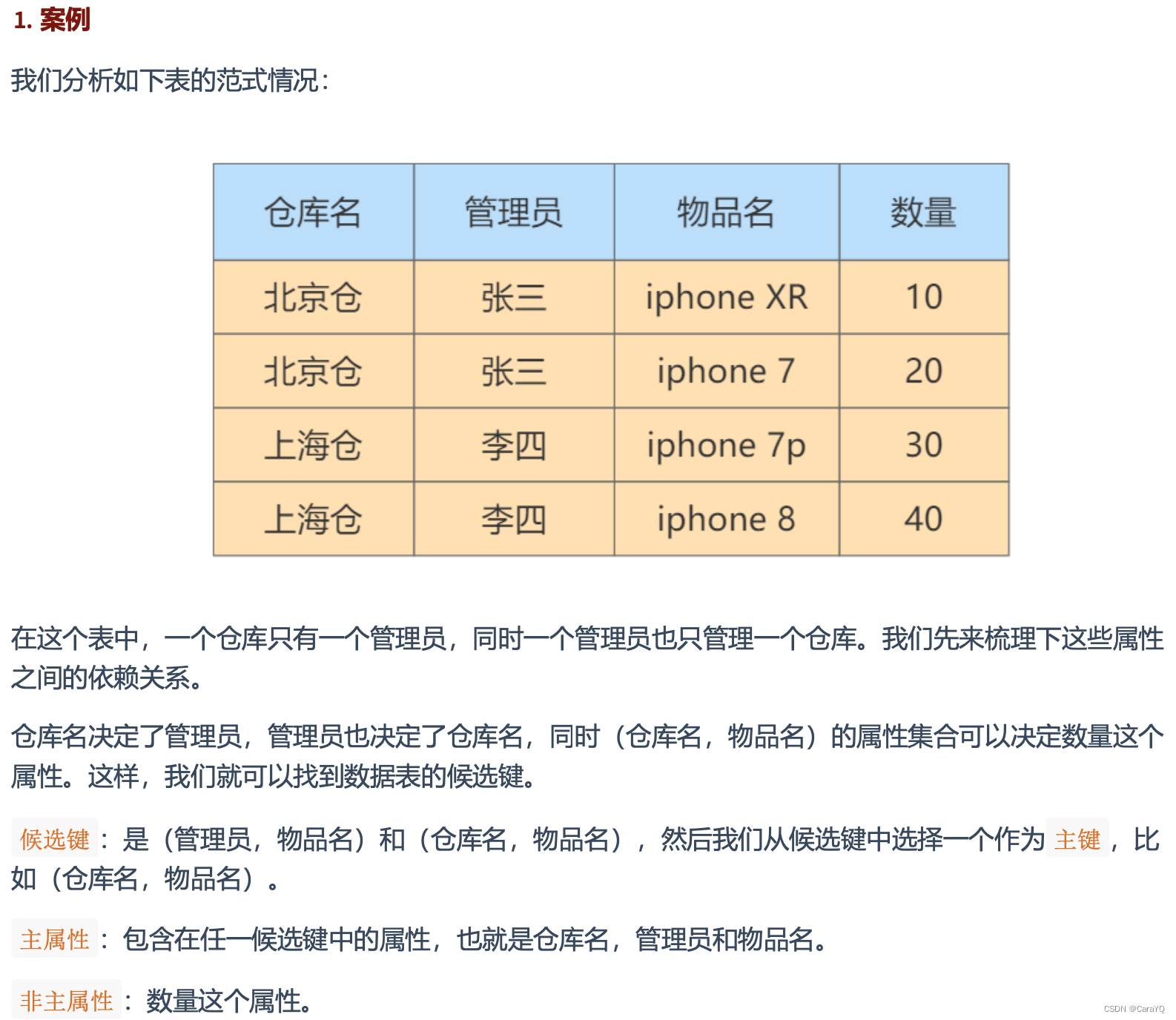
在关系型数据库中,关于数据表设计的基本原则、规则就称为范式。可以理解为,一张数据表的设计结构需要满足的某种设计标准的 级别 。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
范式都包括哪些
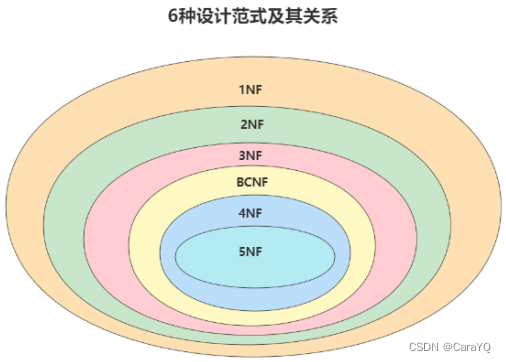
目前关系型数据库有六种常见范式,按照范式级别,从低到高分别是:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。

键和相关属性的概念

超键:能唯一标识一行数据的属性集,其实只要是主键+任意字段就可以构成一个超键
候选键:真正的能唯一标识一行数据的字段,比如人的身份证号
主键只能有一个,候选键可以有多个
候选键的属性就称为主属性
举例:这里有两个表:
球员表(player):球员编号 | 姓名 | 身份证号 | 年龄 | 球队编号
球队表(team):球队编号 | 主教练 | 球队所在地
超键:对于球员表来说,超键就是包括球员编号或者身份证号的任意组合,比如(球员编号) (球员编号,姓名)(身份证号,年龄)等。
候选键:就是最小的超键,对于球员表来说,候选键就是(球员编号)或者(身份证号)。
主键:我们自己选定,也就是从候选键中选择一个,比如(球员编号)。
外键:球员表中的球队编号。
主属性、非主属性:在球员表中,主属性是(球员编号)(身份证号),其他的属性(姓名)
(年龄)(球队编号)都是非主属性。
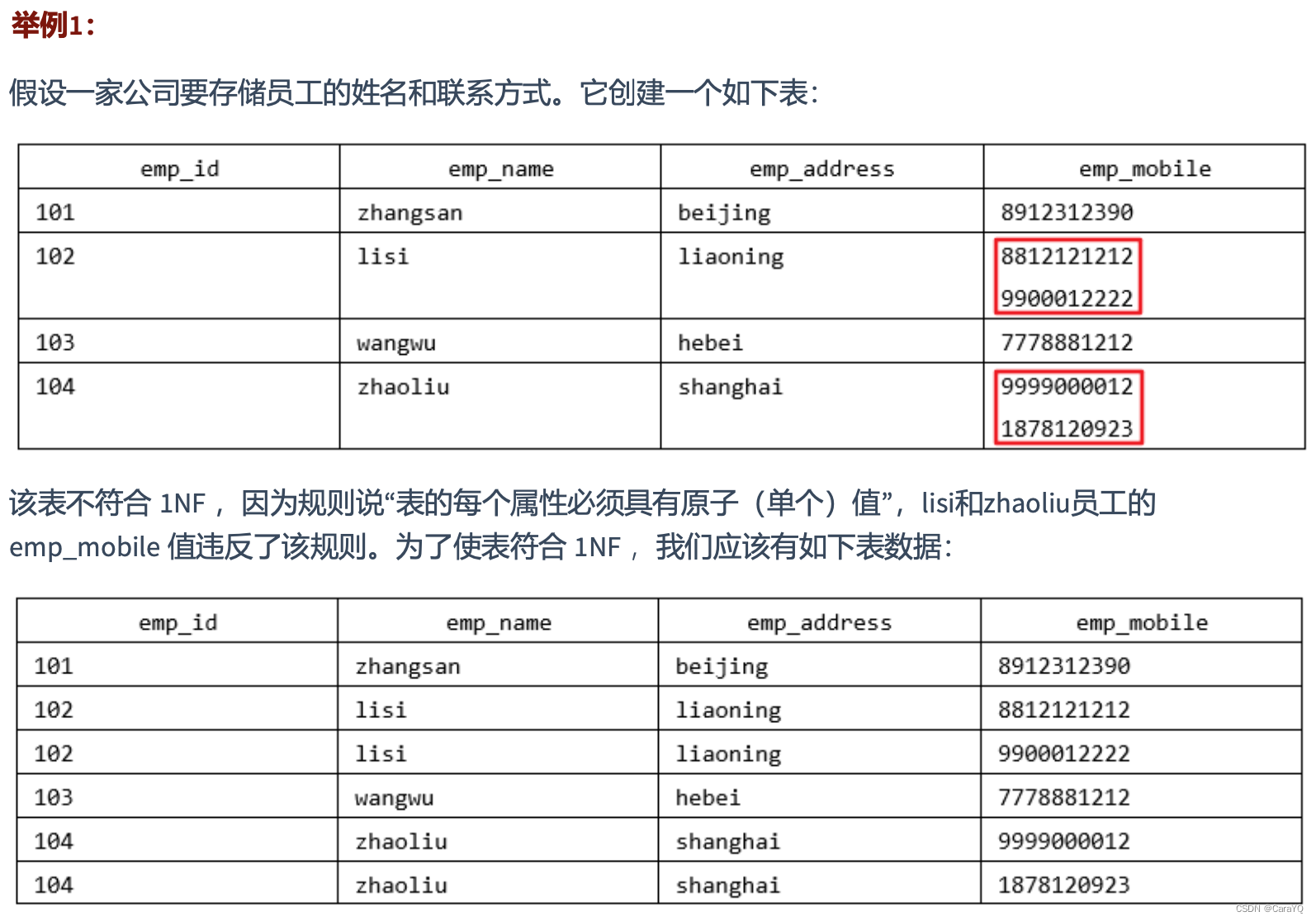
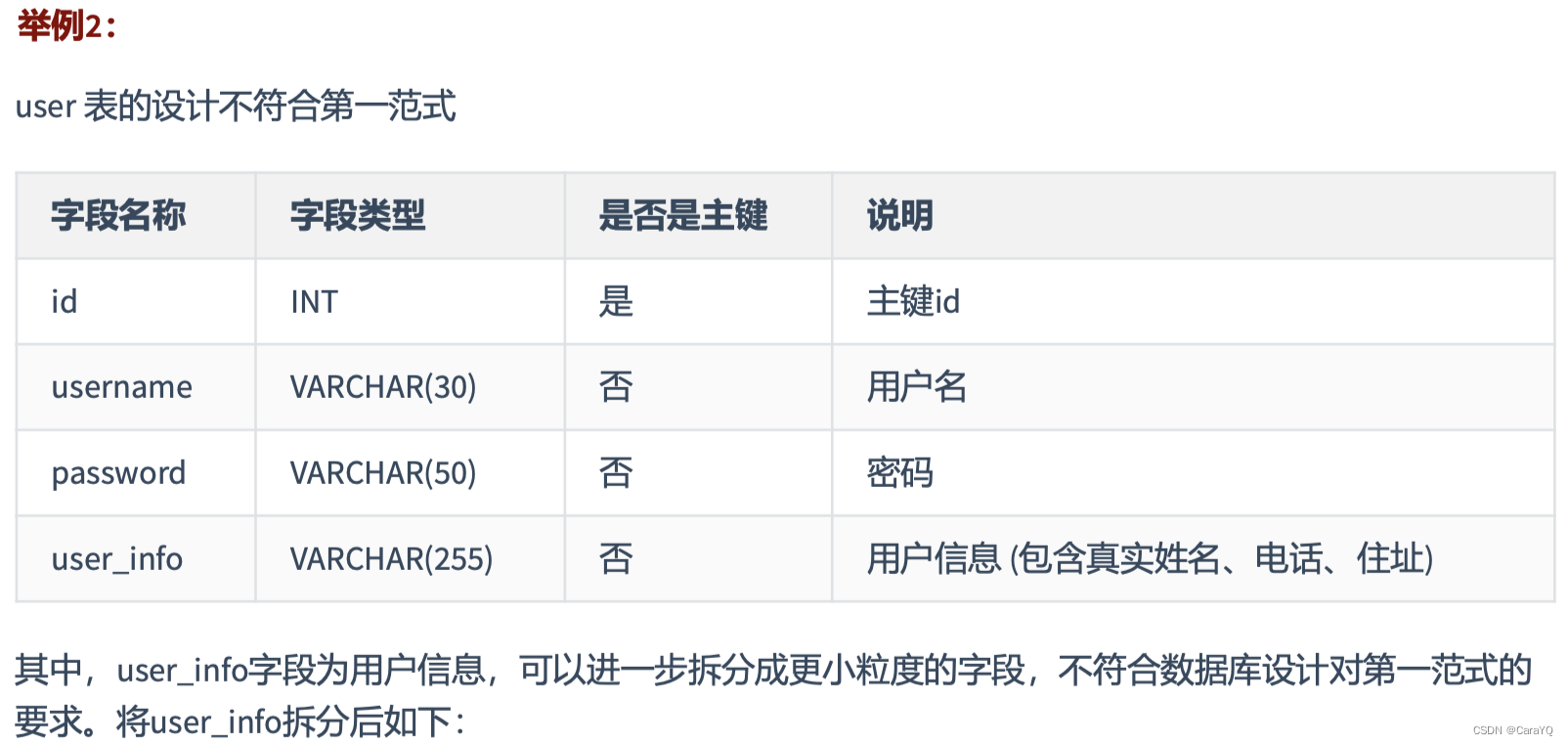
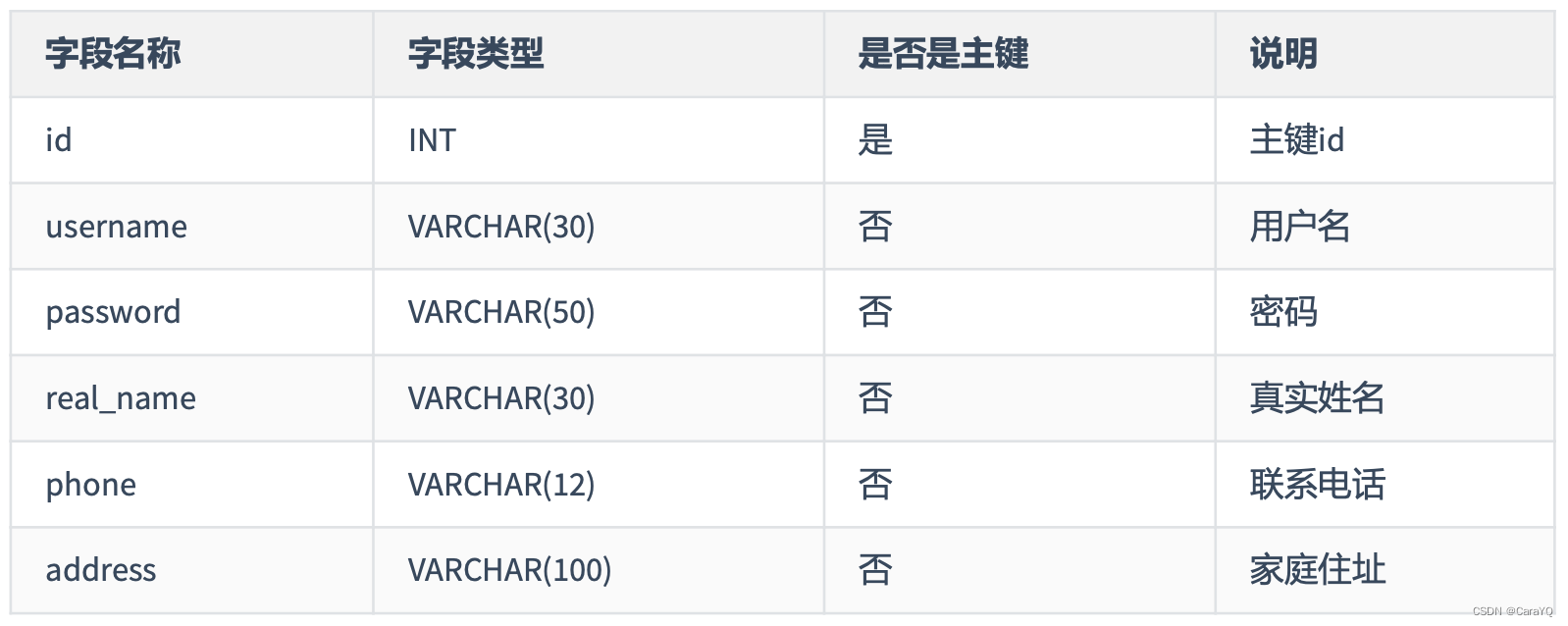
第一范式(1st NF)

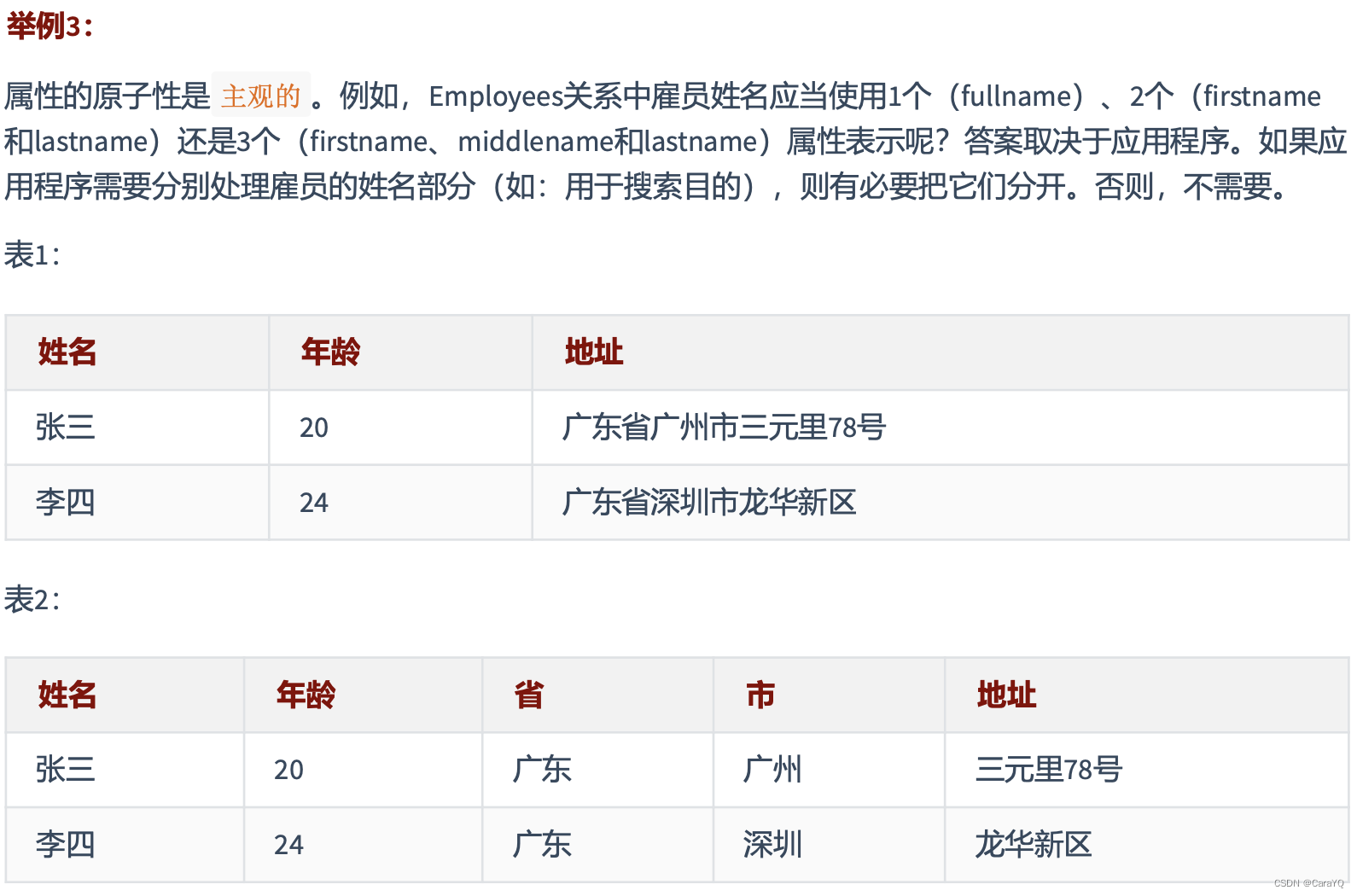
第二范式(2nd NF)

非主键字段完全依赖主键:假如表中字段1、字段2组成了一个唯一主键,其余字段(非主键字段)根据这两个字段的值就能确定唯一值,如果某个非主键字段根据字段1(或字段2)就能确定自己的值,那么这就叫非主键字段依赖主键的一部分,这种情况建议给字段1(或字段2)和该非主键字段建立一张独立的表,然后将该表与原来的表进行关联

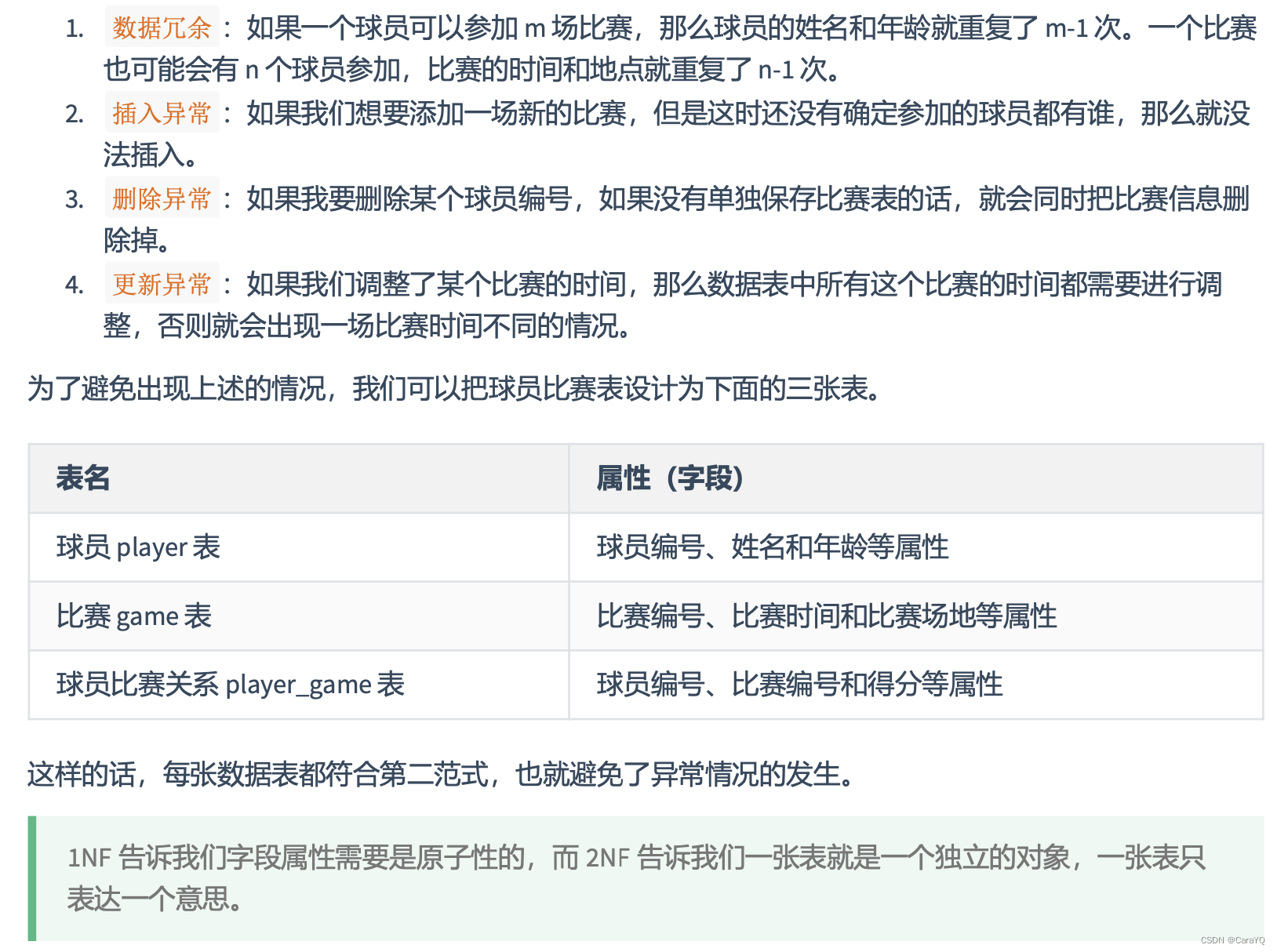
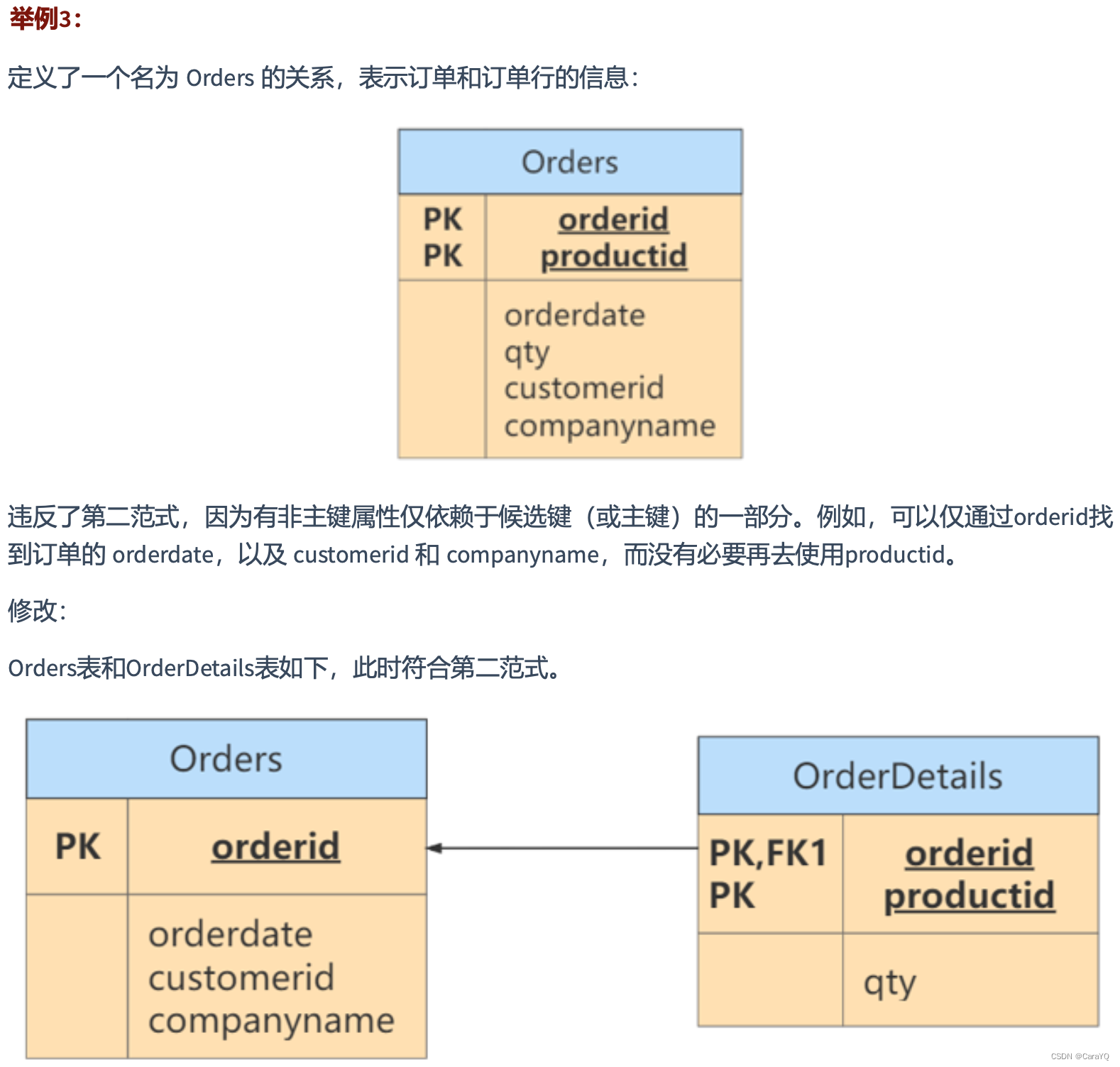
在淘宝购物提交订单时,一个订单中可能有多个商品,如果把所有信息都放在同一张表中,并设置订单号、商品编号为唯一主键,那么就违反了第二范式,因为订单创建时间、公司名、顾客姓名等信息可以根据订单号确定,商品数量可以根据商品编号确定,因此我们可以设置成两张表

第三范式(3rd NF)

列出部门编号后不能再将部门名称、部门简介等与部门相关的信息再加入员工信息表中了,因为部门名称、部门简介等与部门相关的信息都依赖部门编号这个非主键字段,违反了第三范式
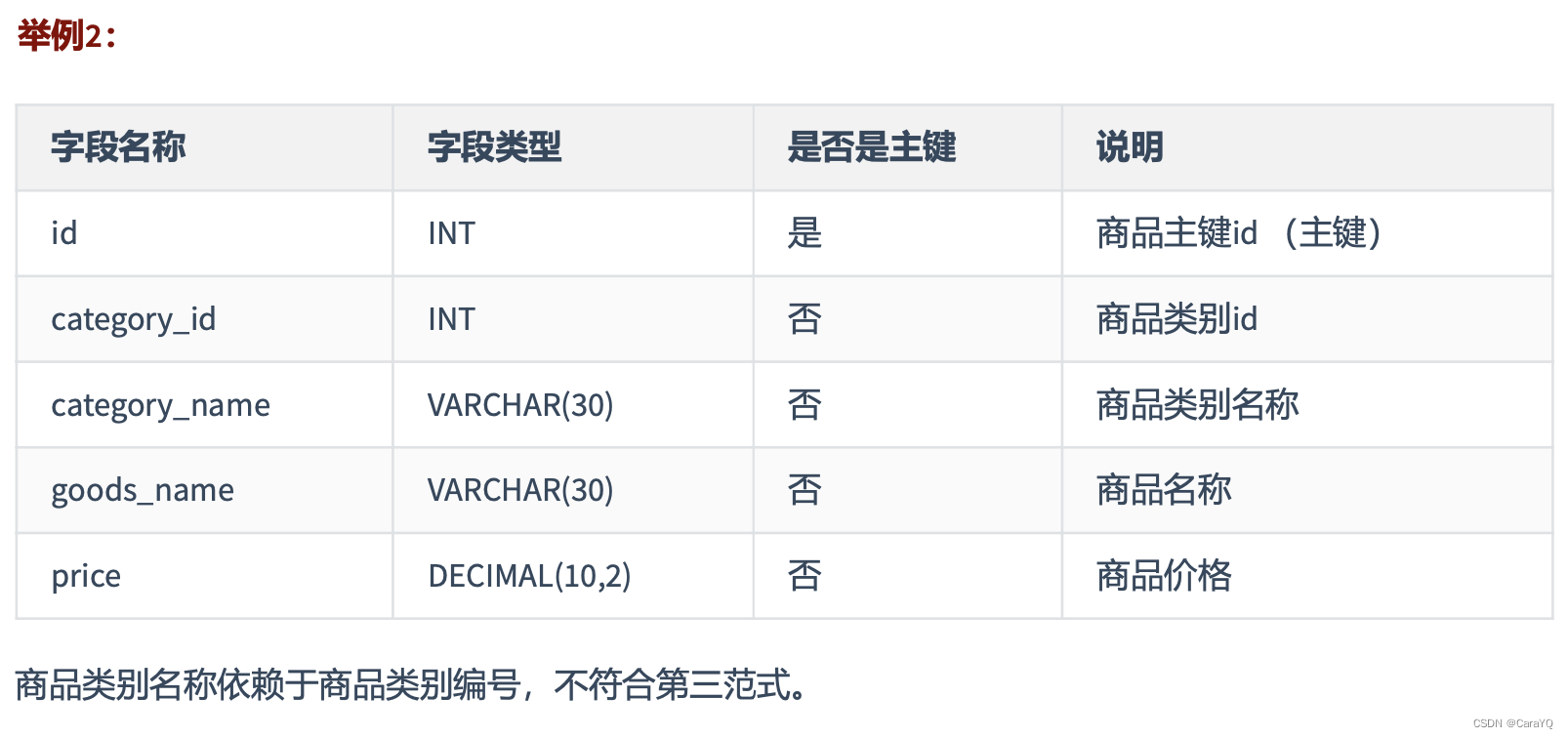
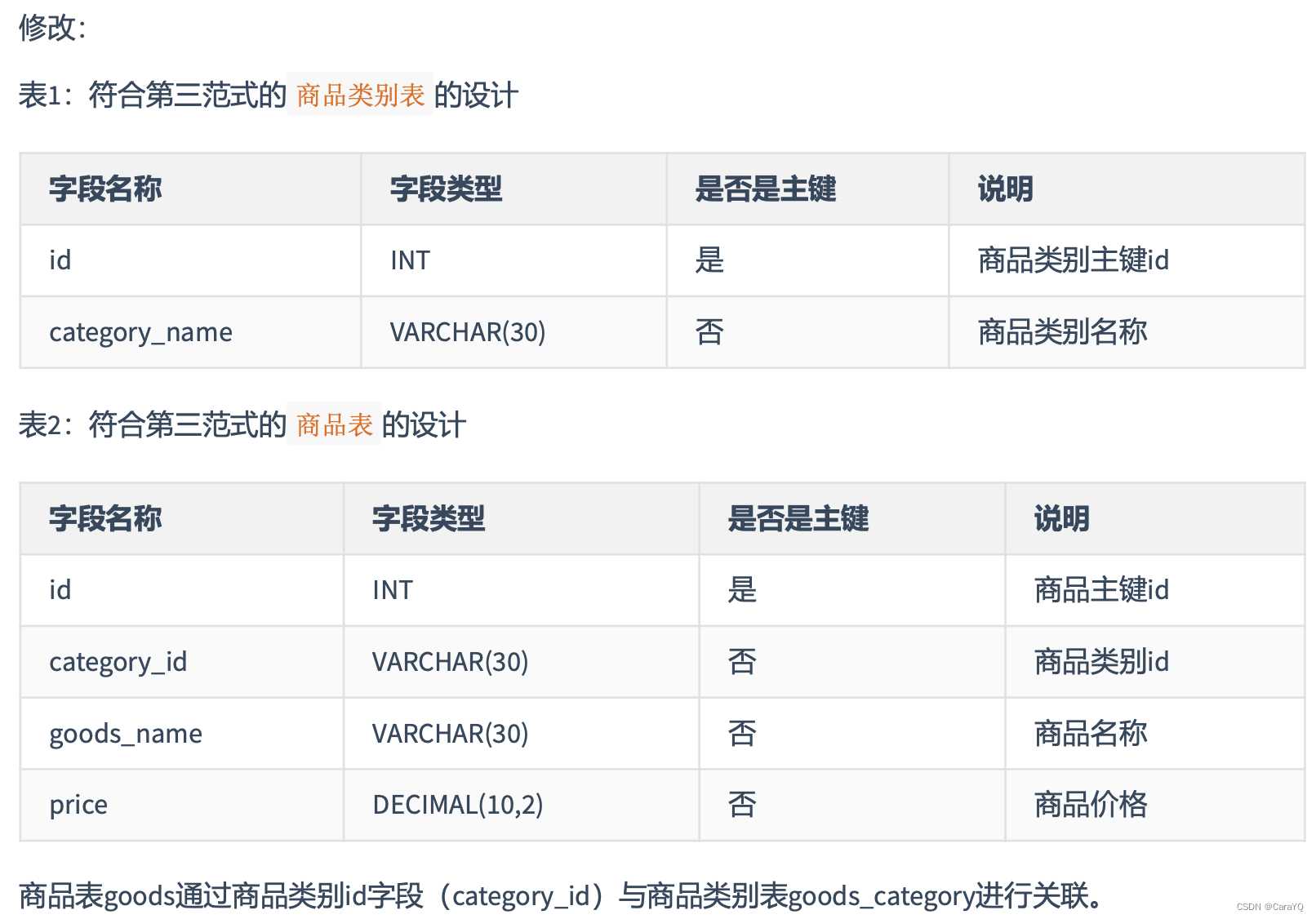
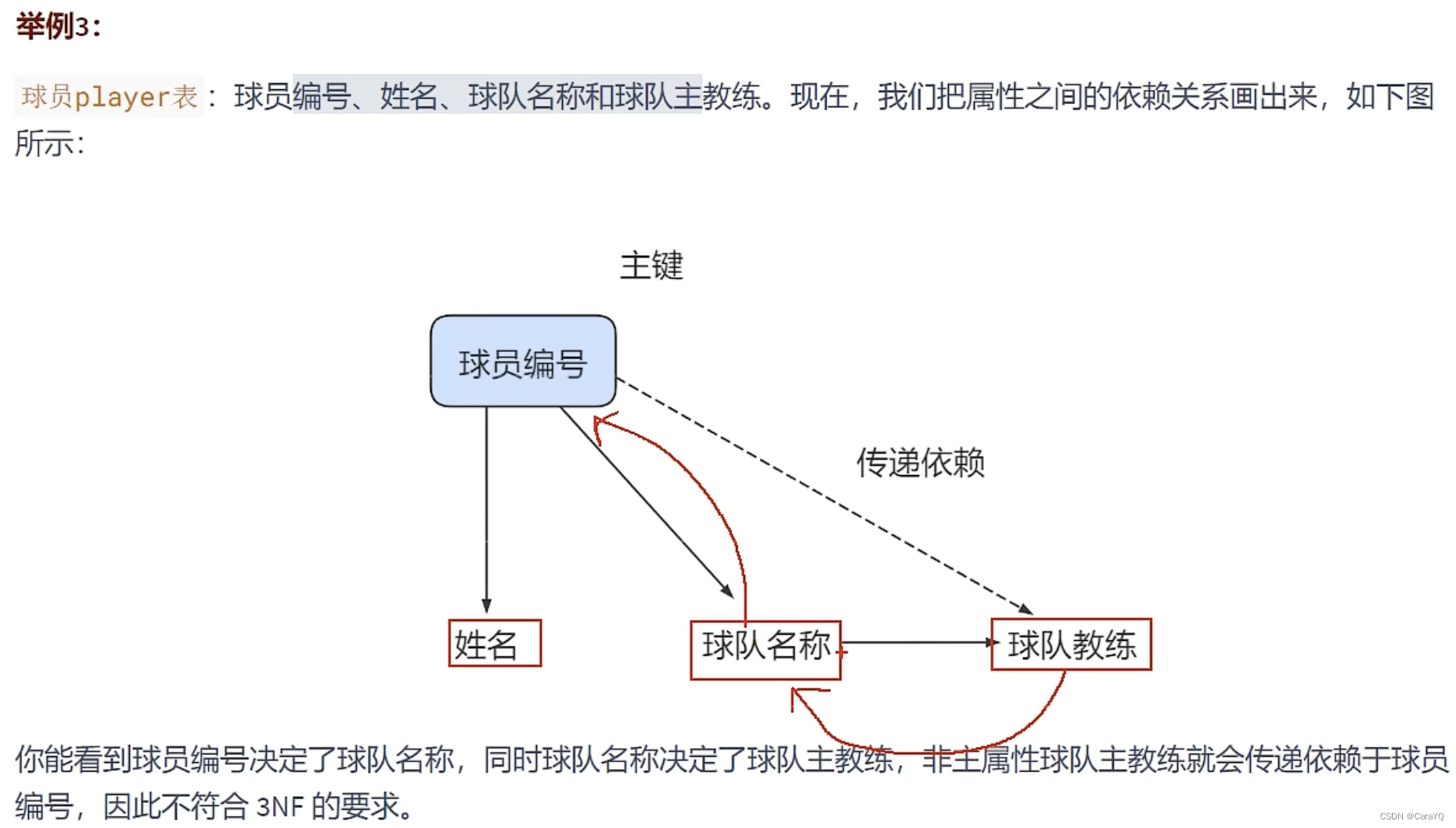

每个非主键属性依赖于主键,依赖于整个主键(不能部分依赖),并且除了主键别无他物(与其他非主键相互独立)

反范式化
概述

应用举例

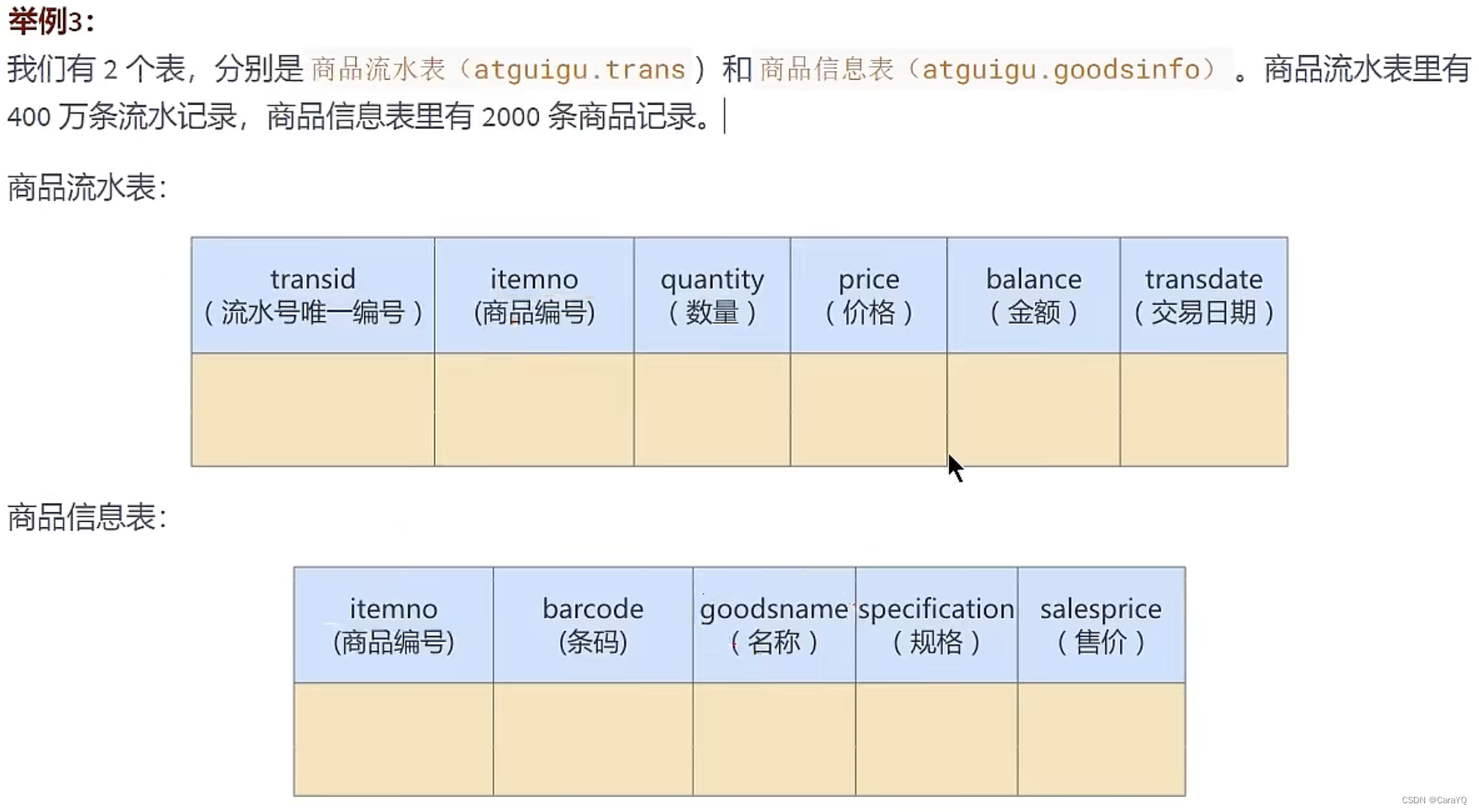
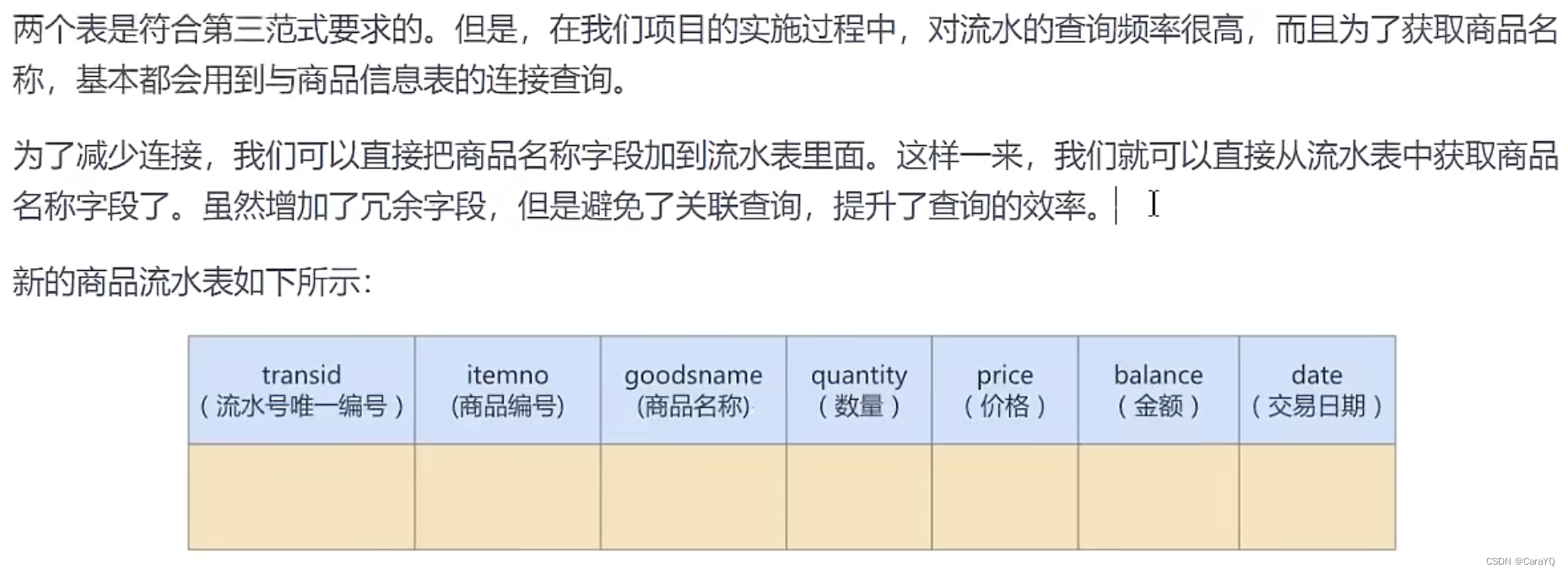

反范式优化实验对比:
- 创建数据库和表:

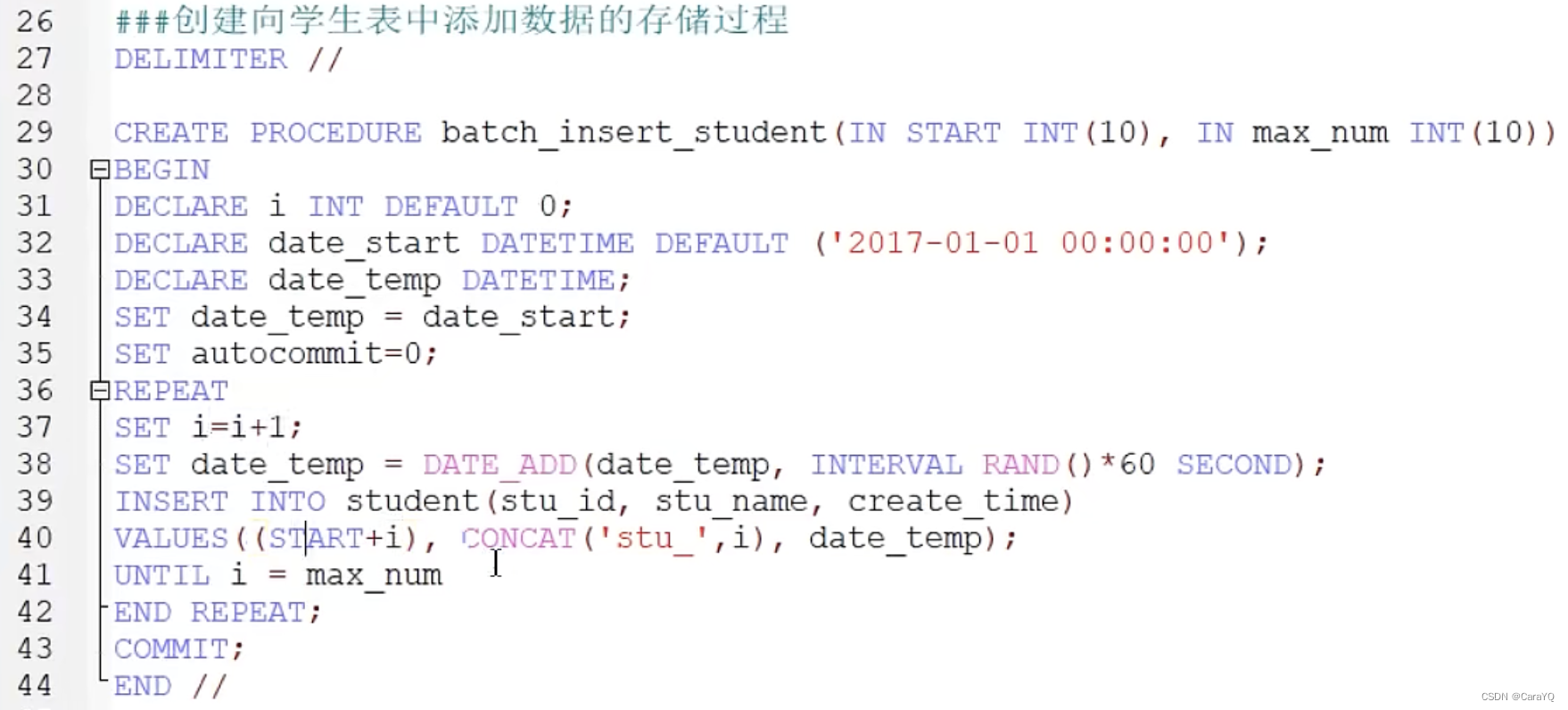
- 添加数据

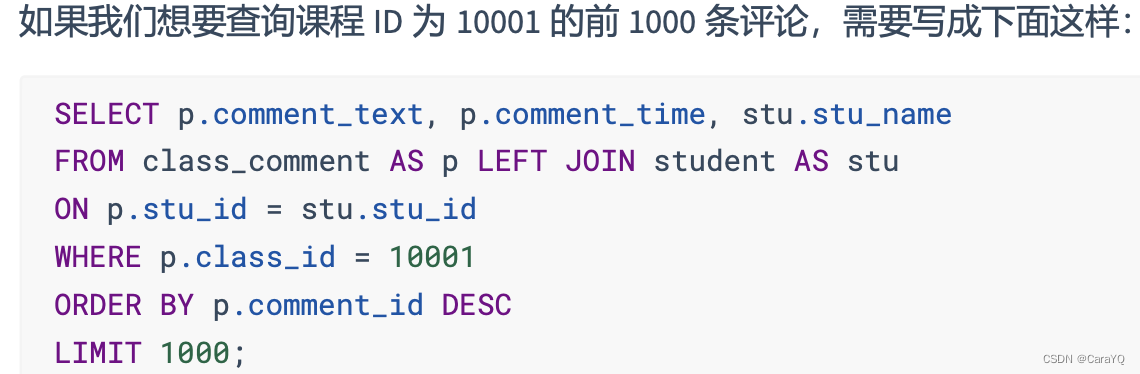
- 满足第三范式,查询
- 查询结果
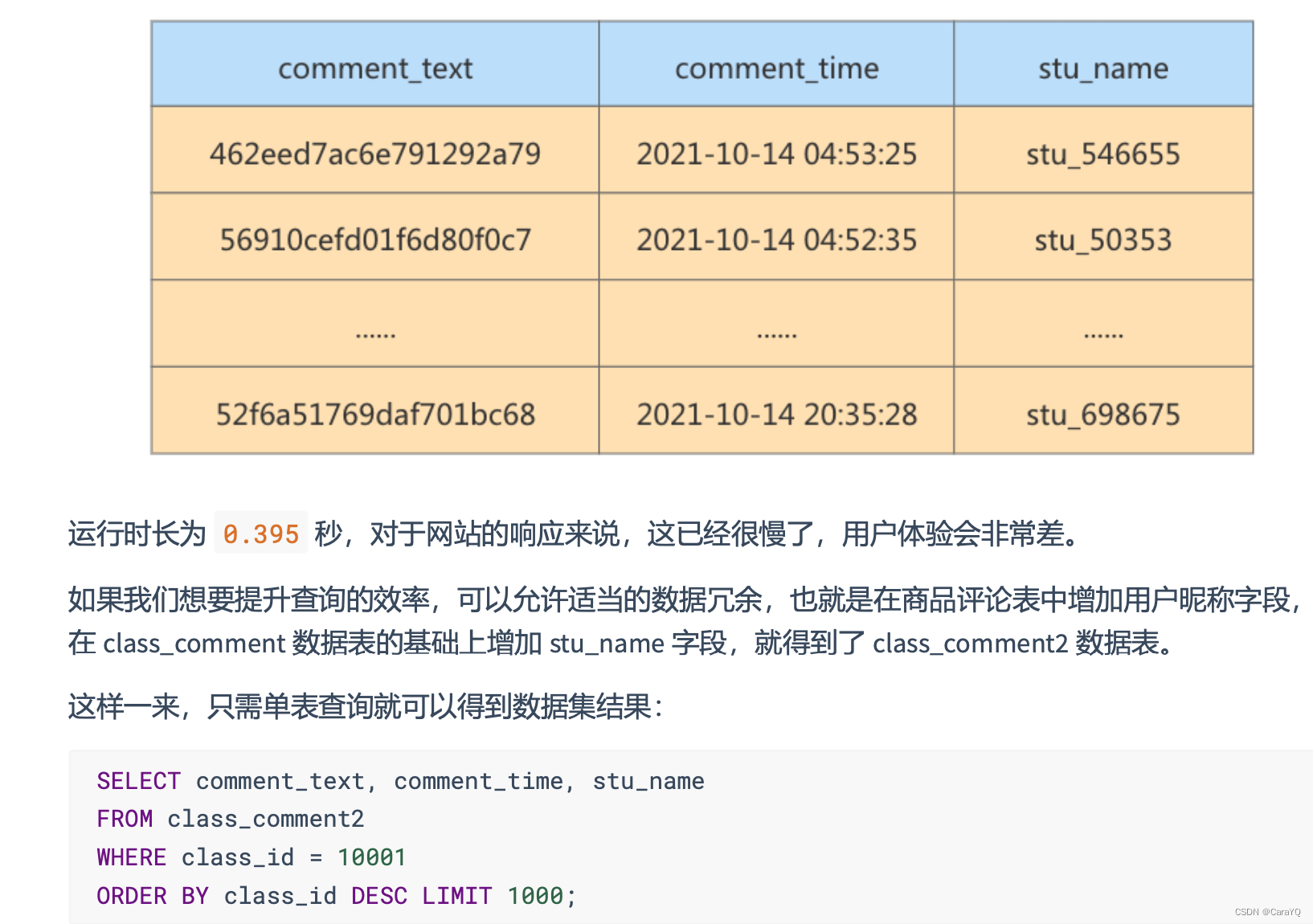
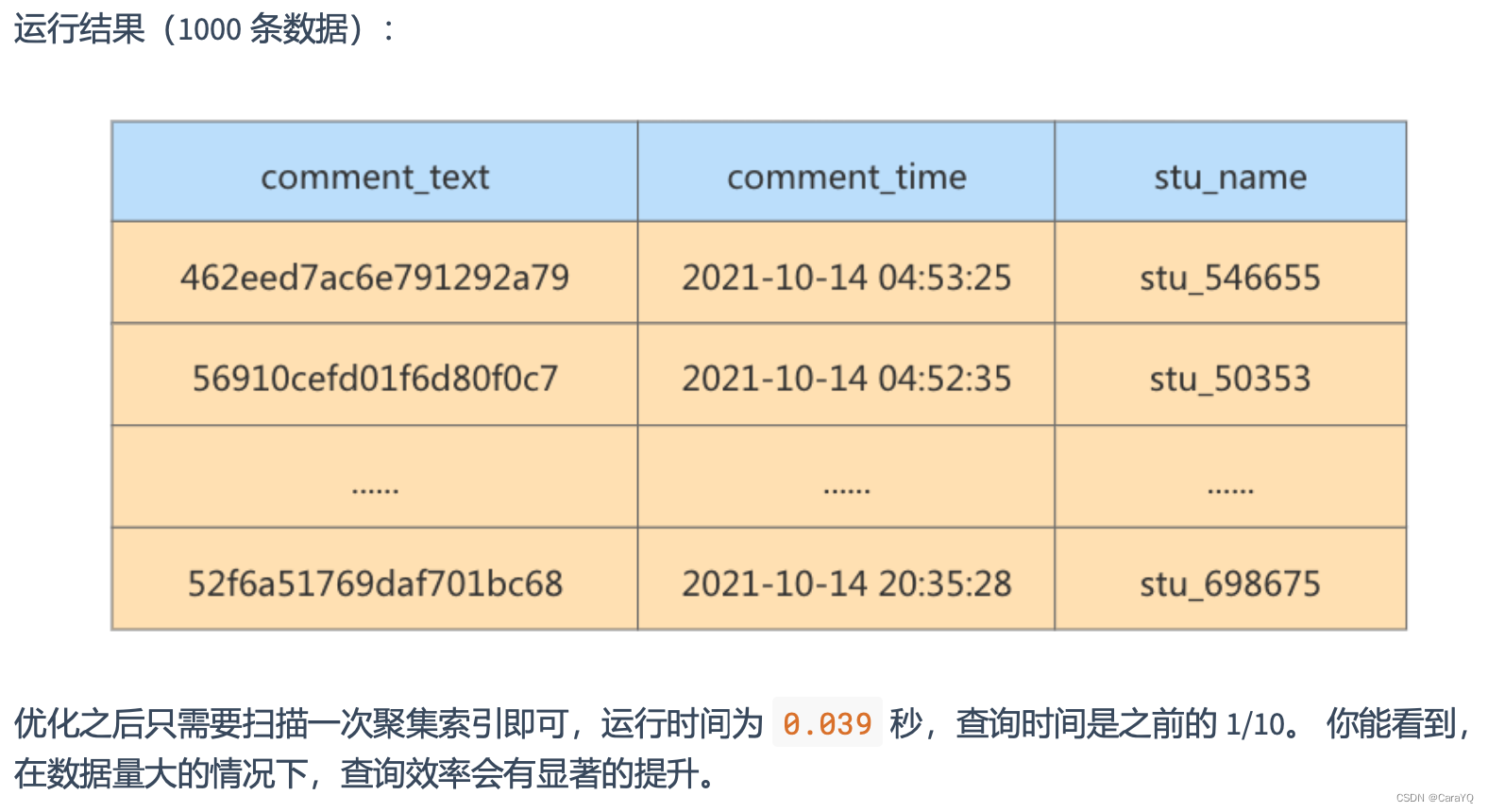
反范式化的新问题
- 存储空间变大了。
- 一个表中字段做了修改,另一个表中冗余的字段也需要做同步修改,否则数据不一致
- 若采用存储过程来支持数据的更新、删除等额外操作,如果更新频繁,会非常消耗系统资源
- 在数据量小的情况下,反范式不能体现性能的优势,可能还会让数据库的设计更加 复杂
反范式的适用场景
当冗余信息有价值或者能大幅度提高查询效率的时候,我们才会采取反范式的优化。
一、增加冗余字段的建议

二、历史快照、历史数据的需要
在现实生活中,我们经常需要一些冗余信息,比如订单中的收货人信息,包括姓名、电话和地址等。每 次发生的 订单收货信息 都属于 历史快照 ,需要进行保存,但用户可以随时修改自己的信息,这时保存这 些冗余信息是非常有必要的。
反范式优化也常用在 数据仓库 的设计中,因为数据仓库通常 存储历史数据 ,对增删改的实时性要求不 强,对历史数据的分析需求强。这时适当允许数据的冗余度,更方便进行数据分析。

先遵循三范式,再考虑反范式化
BCNF(巴斯范式)

案例